
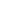


Training eines neuronalen Modells für eine Kamera zur Erkennung von Handynutzung und Rauchen
Projekt in Kürze: Im Auftrag eines Anbieters von Verkehrssicherheitslösungen haben wir ein neuronales Modell für eine Kamera trainiert, die Handynutzung und Rauchen erkennt.
Unsere Ingenieure verwendeten einen Datensatz von über 12.000 Bildern für YOLO, ein Open-Source-Modell für maschinelles Lernen, um eine KI-gestützte Kamerasoftware für Lösungen zur Fahrerüberwachung und andere mögliche Anwendungen zu erstellen: kritische Infrastrukturanlagen und rauchfreie Umgebungen.
Kunde & Herausforderung
Ein Anbieter von Verkehrssicherheitslösungen wandte sich an uns, um mit Hilfe von maschinellem Lernen ein neuronales Modell zu trainieren, das unangemessenes Fahrverhalten erkennen kann, das zu gefährlichen Situationen führen kann: Rauchen und die Nutzung von Mobiltelefonen.
Lösung
Wir verwendeten einen Ansatz zur Objekterkennung mit zwei Klassen. Für die Analyse des Fahrverhaltens und die Erkennung von Ablenkungen erstellten wir unseren eigenen Datensatz mit über 12.000 Bildern; und in 8 Monaten trainierten wir ein neuronales Modell für den Kunden unter Verwendung von drei YOLO-Modellen – Versionen 5, 7 und 8. Das beste Ergebnis für die Erkennung unerwünschten Verhaltens betrug 88 % mit YOLov8.
Datensammlung
Unsere Ingenieure generierten den Datensatz für das Training des neuronalen Modells aus mehreren Open-Source-Datensätzen:
- COCO-Datensatz: Wir wählten etwa 2000 Fotos aus und schlossen ungeeignete aus: Fotos von Tastenhandys und Handys ohne Anrufer. Die Aufgabe des neuronalen Netzes besteht darin, nicht nur ein Telefon zu erkennen, sondern auch eine Person, die telefoniert.
- Open-Source-Datensätze: Wir wählten außerdem mehr als 3500 kontextuell passende Fotos aus.
Wir haben die Rohdaten mit Hilfe von Objektdetektoren kommentiert:
- YOLOv7, das vortrainiert wurde, um Telefone im COCO-Datensatz zu erkennen;
- YOLOv4, das trainiert wurde, um Zigaretten zu erkennen.
Alle Fotos wurden manuell auf die Qualität der Annotation überprüft.
Wir haben außerdem etwa 3000 Fotos ohne Zigaretten und Telefone ausgewählt und getestet. Dieses Verfahren verbessert die Trainingseffizienz und hilft, ein Übertraining des Modells zu vermeiden.
Der endgültige Datensatz enthielt 12522 Bilder:
- 9140 Bilder von Handys und Zigaretten, d.h. gekennzeichnete Bilder;
- 3382 nicht beschriftete Bilder.
Der endgültige Datensatz: 10991 Bilder einer Trainingsgruppe und 1531 Bilder eines Validierungsgruppe.
Trainingsprozess
Um das neuronale Netzwerk zu trainieren, verwendeten wir mehrere Modelle der YOLO-Familie: YOLOv7, YOLOv8 und YOLOv5. Wir testeten verschiedene Trainingsstrategien: Bildgröße, benutzerdefinierte Ergänzungen und benutzerdefinierte Anker. Im Folgenden beschreiben wir die stabilsten Konfigurationen.
Unser Team nutzte mAP oder mean Average Precision (mAP) als Metrik zur Bewertung der Genauigkeit, die ein Analogon zur Genauigkeit in Klassifizierungsaufgaben darstellt. Präzision misst die Genauigkeit Ihrer Vorhersagen, und Recall misst, wie gut Sie alle positiven Beispiele finden.
mAP.5 bedeutet, dass mAP bei 0,5 Intersection over Union (IoU) berechnet wird, und mAP.5.95 bedeutet den durchschnittlichen mAP, der bei verschiedenen IoUs in 0,05-Schritten berechnet wird.
YOLOv7 ist ein hochmodernes Modell, das verschiedene Funktionen bietet, um die besten Trainingsergebnisse zu erzielen, wie z.B. die optimale Transportzuweisungsmethode (OTA), Mosaik-Augmentation und andere.
Zunächst experimentierten wir mit der Größe der Trainingsbilder und erzielten den besten Trainingserfolg mit Bildern im Format 640x640 px. Aufgrund einiger Probleme haben wir diese Bildgröße jedoch zugunsten von Bildern mit einer Größe von 320x320 Pixeln aufgegeben:
- Langsames Training. Das Training mit 640x640 Bildern ist fast 4-mal langsamer als das Training mit 320x320.
- Langsame Inferenzphase. Die Inferenz mit 640x640 Bildern ist 4-mal langsamer als mit 320x320. 640x640 Bilder sind für die Echtzeit-Inferenz auf eingebetteten Geräten nicht geeignet.
Das YOLOv7-Modell wurde für 700 Epochen trainiert mit einem Ergebnis von 75% mAP 0.5:
Trainingsergebnisse des YOLOv7-Modells
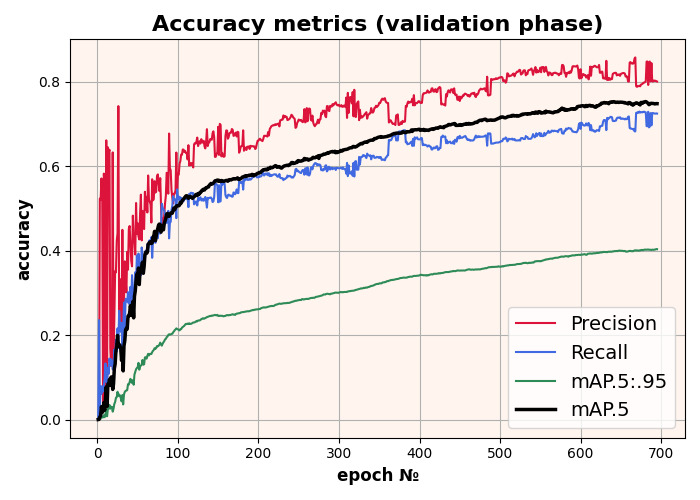
Wir trainierten das YOLOv8-Modell für 50 Epochen mit 640x640 Eingabebildern, ausgehend vom vortrainierten COCO-Modell. Das beste mAP-Ergebnis beträgt 0,88 bei einem 0,5-Skalierungsfaktor.
Trainingsergebnisse des YOLOv8-Modells
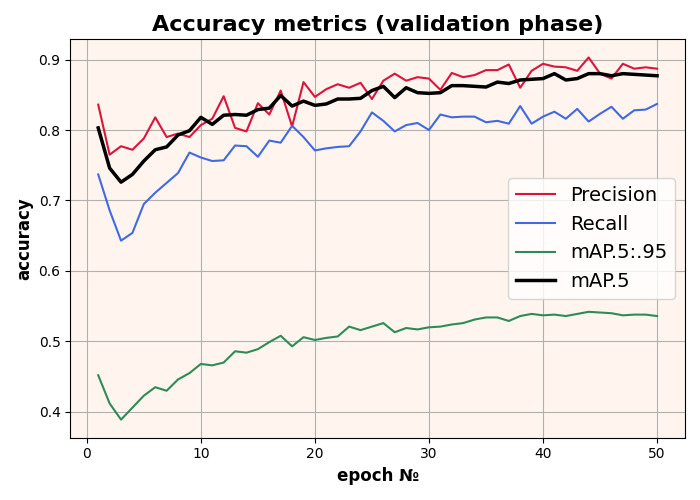
Das Modell wurde mit 320x320 Eingabebildern trainiert. Das beste mAP-Ergebnis beträgt 0,82 bei einem 0,5-Skalierungsfaktor.
Trainingsergebnisse des YOLOv5-Modells
Es gibt verschiedene Ansätze zur Gewichtsreduktion:
- Unstrukturierte Reduktion berücksichtigt nicht die gesamte Architektur und kürzt Gewichte nur nach ihrem eigenen Einfluss. Dieser Ansatz ist ineffizient, da er die Modellarchitektur nicht reduziert – Nullgewichte werden ebenfalls im Speicher gespeichert – und die Modellausgabezeit nicht beeinflusst.
- Beim strukturierten Pruning wird versucht, die gesamte Architektur zu berücksichtigen und nicht nur die Gewichte, sondern auch die Merkmalskarten auszuschließen. Dadurch wird die Modellarchitektur verkleinert und somit die Zeit für die Modellinferenz verkürzt.
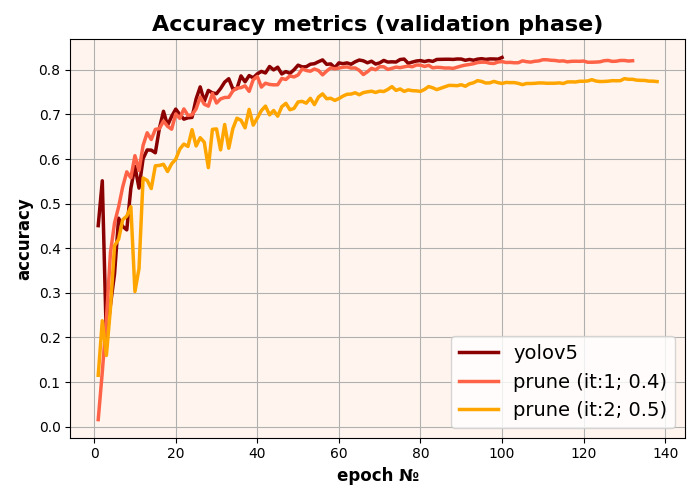
Ergebnisse der YOLOv5-Modellbereinigung
Die Trainingsergebnisse aller Modelle sind im untenstehenden Diagramm dargestellt. Das beste Ergebnis wurde beim Training des YOLOv8-Modells erzielt – 88% Genauigkeit.
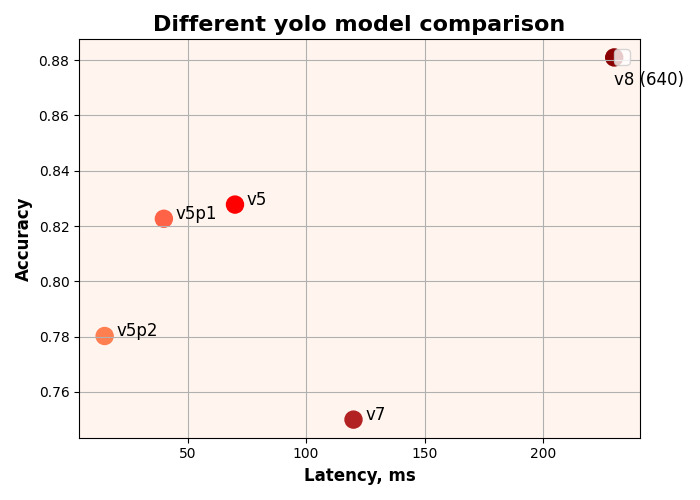
Vergleich der Trainingsergebnisse für alle YOLO-Modelle
Geschäftswert
Die Einführung eines neuronalen Modells, das zwischen Rauchen und der Nutzung von Mobiltelefonen unterscheiden kann, wird die bestehenden Fahrerüberwachungslösungen unseres Kunden verbessern und das Fahren noch sicherer machen.
Kameras, die die Nutzung von Mobiltelefonen und Rauchen erkennen, können an anderen Orten installiert werden:

1. Kritische Infrastruktureinrichtungen wie Kraftwerke oder Chemiewerke, wo das Rauchen aus Sicherheitsgründen oft verboten ist.

2. Arbeitsplätze, an denen Rauchen verboten ist oder die Nutzung von Mobiltelefonen von der Arbeit ablenkt und eine Sicherheitsgefahr darstellt.

3. Öffentliche Orte, an denen ein rauchfreies Umfeld geschaffen werden soll: Einkaufszentren, Flughäfen, Konzerthallen, Stadien, Bildungseinrichtungen usw.






