
Wie wir ein neuronales Netzwerk zum Zählen von Personen für Transport, Einzelhandel und intelligente Städte trainiert haben


Deep Learning steigert die Produktivität und senkt die Kosten in verschiedenen Geschäftsanwendungen. In diesem Artikel zeigen wir, wie unsere Ingenieure ein neuronales Netz für die Personenzählung entwickelt haben. Diese Lösung kann nun im öffentlichen Verkehr, in intelligenten Gebäuden, im Einzelhandel und beim Warteschlangenmanagement eingesetzt werden.
Inhaltsverzeichnis
Wo neuronale Netze eingesetzt werden
Wie Kopf- und Gesichtserkennungssysteme funktionieren
Wie das neuronale Netz trainiert wird
Feinabstimmung des Deep-Learning-Modells mit iterativem Datensatz
Deep Learning ist eine Art des maschinellen Lernens, bei dem neuronale Netze mit großen Datenmengen trainiert werden. Diese Technologie ermöglicht die Automatisierung komplexer Geschäftsprozesse und die Implementierung von Analysen für datengesteuerte Entscheidungen in verschiedenen Bereichen.
In den letzten fünf Jahren ist der Markt für Deep Learning fast um das 22-Fache (!) gewachsen. Ende 2022 wurde er auf 49,6 Milliarden US-Dollar geschätzt.
Wo neuronale Netze eingesetzt werden
Vor der Einführung neuronaler Netze wurden menschliche Zählaufgaben mithilfe eines menschlichen Bedieners und Überwachungskameras sowie optischer Sensoren in Drehkreuzen (sofern vorhanden) gelöst. Computer-Vision- und Deep-Learning-Technologien vereinfachen und automatisieren diesen Prozess in vielen Bereichen:

Öffentlicher Nahverkehr. Lösungen zur Personenzählung helfen bei der Steuerung des Fahrgastaufkommens, der Analyse von Stoßzeiten und Verkehrsstaus. Mithilfe von Analysedaten können Stadtverwaltungen die Fahrpläne des öffentlichen Nahverkehrs optimieren: Verkürzung der Intervalle zwischen den Fahrzeugen, zusätzliche Fahrten auf der Strecke usw.

Intelligente Gebäude. KI-basierte Kameras erleichtern den Betrieb und die Wartung von Gebäuden. Hier sind nur einige Szenarien, wie maschinelles Lernen für intelligente Gebäude eingesetzt werden kann:
- Überwachung der Kapazität von Büro- und Besprechungsräumen in einem hybriden Arbeits- oder Coworking-Format;
- Zählung von Personen und Überwachung der Belegung und der Einhaltung der Abstandsregeln;
- Anpassung von Heizungs-, Klima- und Beleuchtungssystemen an den Bedarf;
- Überwachung der Aufzugsbelegung und Vermeidung von Überlastungen.
Einzelhandel. Maschinelles Lernen in der Einzelhandelsanalyse optimiert die Arbeitsbelastung des Personals. Die gewonnenen Daten helfen, das Kundeninteresse an Produkten und Auslagen zu untersuchen, die Laufwege der Menschen durch die Verkaufsfläche zu erfassen und das Ladendesign zu ändern: Abschnitte in einer bequemen Reihenfolge platzieren oder Werbematerialien bevorzugen.
Warteschlangenmanagement. Kameras mit Gesichtserkennung helfen bei der Verwaltung von Warteschlangen an Flughäfen, Bahnhöfen und großen Geschäften, indem sie die Anzahl der Personen in der Schlange und ihre Wartezeit erfassen. Wenn die Daten zeigen, dass die Warteschlange schnell wächst und sich nur langsam bewegt, ist dies ein Signal, zusätzliche Check-in-Schalter, Kassierer oder Call-Personal einzusetzen.
Mobilität in der Stadt. Intelligente Kameras für die Videoüberwachung machen das städtische Umfeld für Menschen mit Behinderungen oder Eltern mit Kinderwagen zugänglich. Solche Kameras in öffentlichen Verkehrsmitteln helfen den Fahrern, Fahrgäste zu erkennen, die Hilfe benötigen: eine Rampe zum Aussteigen oder einen mechanischen Aufzug.
Wie Gesichts- und Kopf-Erkennungssysteme funktionieren

Schauen wir uns an, wie ein neuronales Netzwerk in Verbindung mit einer Kamera funktioniert. Diese Kombination wird in den meisten Videoüberwachungslösungen verwendet. Zuvor haben wir in unserer Fallstudie über einen intelligenten Fahrradparkplatz mit der SONY Spresense AI-Kamera beschrieben, wie dies funktioniert.
Hier sind die wichtigsten Schritte im Prozess der Objektzählung im Kameravideo:
- Erfassung von Bildern von CCTV-, IP- oder Spezialsensoren, die den Zielbereich abdecken.
- Verbesserung der Bildqualität: Filterung, Rauschunterdrückung, Stabilisierung und Klarheit von Bildern oder Videobildern.
- Erkennung von Objekten mithilfe von Computer-Vision-Algorithmen, einschließlich Single-Shot-Detection (SSD).
- Zählung von Objekten und Analyse ihrer Merkmale: Personendichte, Wartezeit, Bewegungsmuster usw.
- Integration und Visualisierung von Daten: Anzeige von Dashboards und Übertragung an Steuerungssysteme und Anwendungen.
Damit ein solches System ordnungsgemäß funktioniert, muss das neuronale Netz trainiert werden. Dies ist ein komplexer, aber sehr spannender Prozess, den wir im Folgenden beschreiben. Derzeit trainieren Promwad-Ingenieure im Rahmen eines laufenden maschinellen Lernprojekts in der Automobilindustrie ein neuronales Netz für die Gesichts- und Kopferkennung.
Wie das neuronale Netz trainiert wird
Die Erkennung des Kopfes ist eine Teilmenge der Objekterkennungsaufgaben. Warum ist es wichtig, den Kopf zu identifizieren? Bei einer Reihe von Anwendungen ist es nicht ausreichend oder möglich, die Anwesenheit einer Person zu erkennen. Die Gestalt einer Person kann teilweise in einer Menschenmenge verborgen sein oder die Kamera kann eine Menschenmenge von oben oder von der Seite filmen.

Ein neuronales Netzwerk, das darauf trainiert ist, Köpfe und Gesichter zu erkennen. Videoquelle: „Stabile Verfolgung mehrerer Ziele in Echtzeit-Überwachungsvideos“ von Benfold, Ben und Reid, I. CVPR 2011
Um Personen zu zählen, muss ein neuronales Netzwerk mehrere Dinge tun:
- die Anwesenheit einer Person im Bild erkennen;
- den Bereich finden, in dem sich der Kopf befindet;
- die Koordinaten des den Kopf umgebenden Bildausschnitts bestimmen;
- dem Objekt eine Kennung zuweisen, damit es von Bild zu Bild verfolgt werden kann.
Wir werden die SSD-Objekterkennungsarchitektur verwenden – einen der beliebtesten Algorithmen.
Der einfachste Fall einer Verlustfunktion beim maschinellen Lernen
Feinabstimmung des Deep-Learning-Modells mit iterativer Datensatzerweiterung für die Gesichtszählung
Beim Training eines neuronalen Netzwerks stehen wir vor zwei wichtigen, miteinander verbundenen Problemen:
- Wo und wie viele Bilder müssen wir für unser Training aufnehmen, um eine akzeptable Genauigkeit des neuronalen Netzwerks zu erreichen?
- Wie viele Iterationen sollten durchgeführt werden, damit das neuronale Netzwerk ausreichend lernt?
Die Lernzeit und Genauigkeit des Algorithmus hängt davon ab, wie diese Probleme gelöst werden.
Wir haben uns für einen iterativen Ansatz entschieden, um das neuronale Netz zu trainieren, indem wir bei jeder Iteration einen neuen Teil der Bilder laden. Dieser Ansatz löst ein potenzielles Leistungsproblem mit der Plattform, auf der das Modell trainiert wird: Wir nehmen mehr Daten auf und erweitern den vorhandenen Datensatz iterativ. Der Zyklus „Sicherstellung der Modellleistung → Erweiterung des Datensatzes → Feinabstimmung des Modells“ wird wiederholt, bis wir ein gutes Ergebnis erhalten.
Das Training unseres neuronalen Netzwerks dauerte 7 Iterationen. In der Null-Iteration trainierten wir das Modell anhand eines Datensatzes aus kostenlosen Quellen . Dieser bestand aus 2405 Bildern, die Köpfe und Gesichter mit unterschiedlichen Merkmalen darstellten: Winkel, Größe und Dichte.

Bilder aus einem kostenlosen Datensatz werden verwendet, um das Modell für die Null-Iteration zu trainieren. Quelle: github.com
Wir setzten das Training fort und luden neue Teile von Fotos. Bei der sechsten Iteration erzielten wir eine Genauigkeit von ~92 % und beendeten das Training an dieser Stelle. Je weiter der Lernprozess voranschreitet, desto geringer ist die Genauigkeitssteigerung. In einigen Fällen zeigt das Modell mit jeder Iteration genauere Ergebnisse, aber die Leistung nimmt bei der nächsten Iteration ab. Dies geschah aufgrund interner Fehler oder weil die falschen Eingaben geladen wurden.
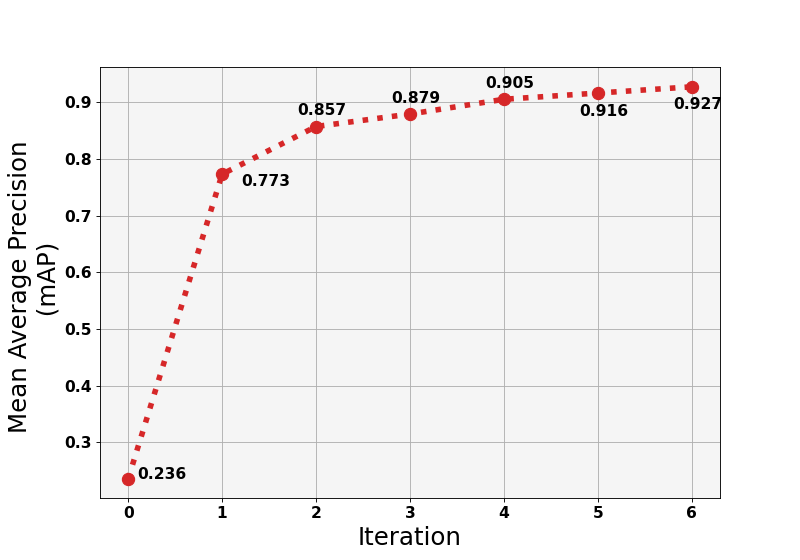
Iterationsdiagramm unseres neuronalen Netzwerktrainings für die Personenzählung
Wenn wir ein Modell in Iterationen trainieren, erweitern wir einerseits die Daten, auf denen es trainiert wird. Andererseits kontrollieren wir die Genauigkeit und können die Anzahl der zusätzlichen Iterationen vorhersagen.
Wir haben einen Dienst für das iterative Lernen unseres Neuromodells geschaffen, der mehrere Open-Source-Dienste und -Tools umfasst. Unser iterativer Prozess umfasst mehrere Schritte:
- Überwachung des Trainingsprozesses. Mit einem spezialisierten Dienst können wir verschiedene Metriken wie Verlust, Karte usw. protokollieren – so verstehen wir das Verhalten des Modells im Trainingsprozess.
- Ableitung neuer Daten. In dieser Phase erstellen wir Vorhersagen (Ausgabe) für die neu ausgewählten Daten. Vorhersagen im COCO-Format (Common Objects in Context) werden für die zukünftige Annotation benötigt, um Wahrheitsrahmen zu erstellen. Dieses Verfahren verkürzt die Zeit erheblich, da der Annotationsprozess einer der zeitaufwendigsten beim maschinellen Lernen ist.
- Verfeinerung der Annotationen. Nach der Ausgabe erhalten wir eine Datei mit Vorhersagen von Werten für die Köpfe in der neuen Datencharge. Diese Vorhersagen müssen verfeinert werden, da die Modelle nicht perfekt sind. Wir laden diese Datei in das Computer Vision Annotation Tool (CVAT) und verfeinern die Vorhersagen manuell.
Als Ergebnis haben wir ein Neuromodell, das Gesichter und Köpfe aus verschiedenen Winkeln mit einer Genauigkeit von 92 % erkennt und in Überwachungssystemen an öffentlichen Orten, Flughäfen, Bahnhöfen, großen Verkehrsknotenpunkten und in der Einzelhandelsanalyse eingesetzt werden kann. Wir sind bereit, diese Lösung für Ihr Unternehmen zu nutzen, sie an die spezifische Aufgabe anzupassen und die Erkennungsgenauigkeit auf das erforderliche Niveau zu bringen.
* * *
Lösungen zur Personenzählung tragen zur Verbesserung der Sicherheit in Gebäuden und belebten Bereichen bei. Diese Lösungen basieren auf Deep-Learning-Algorithmen und liefern zuverlässige und genaue Ergebnisse in Echtzeit, selbst in komplexen Szenarien.
Fortschritte in der Technologie und die Entwicklung ausgefeilterer Sensoren werden Unternehmen dazu ermutigen, Gesichtserkennungssoftware zu entwickeln und neuronale Netze präzise zu trainieren. Es werden effizientere und intelligentere Systeme geschaffen, die den Bedürfnissen von Wirtschaft und Gesellschaft gerecht werden.
Als Unternehmen, das sich auf die Entwicklung von maschinellem Lernen spezialisiert hat, bieten wir unseren Kunden Dienstleistungen an, von der Beratung bis hin zur Entwicklung unternehmensspezifischer Lösungen. Kontaktieren Sie uns und wir erklären Ihnen, wie unsere Ingenieure eine auf Ihr Unternehmen zugeschnittene Lösung zur Personenzählung entwickeln können.
Unsere KI-gestützten Lösungen




